스프링 클라우드 기초 사용법 및 소개(1)
스프링 클라우드(Spring Cloud) 소개
이 글은 MSA에 대해 기초적인 내용은 이미 알고 있다는 가정하에 설명하는 글이다.
Spring Cloud는 MSA를 실습해보기 위한 가장 심플한 환경을 제공해준다.
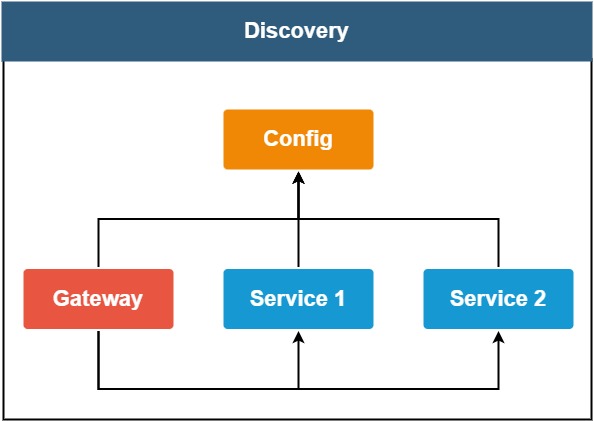
위의 그림은 Spring Cloud 기본적인 연결 구조다.
하나하나 알아보자.
모든 모듈들은 Discovery가 관리한다.
클라이언트가 요청(Request)을 하면 Gateway를 통해서 각각의 마이크로서비스로 전달되고 Response도 역시 Gateway를 통해서 나가게 된다.
그래서 Service 1이 Port 번호가 몇번이든 간에 외부 Request는 오로지 Gateway를 통해서만 받으므로 오로지 클라이언트 연결 접점부는 Gateway Port 번호만 알고 있으면 된다.
깃헙에 Discovery와 Gateway, Service 1 2로 이루어진 예시 Spring Cloud 환경의 예시 프로젝트를 올려놓았으니 같이 보면서 확인해봐도 좋을 듯 하다.
스프링 클라우드의 단점
당연하게도 스프링 이외의 서버는 작동하지 않는다.
Kubernetes를 통해서 작업하면 Node 기반의 서버도 MSA 환경으로 통합이 가능하지만 Spring Cloud는 오로지 스프링만 가능하다.
또한 서비스 장애 발생시 오토 스케일 아웃은 스프링 클라우드에선 기능이 없지만 Kubernetes에는 있다
스프링 클라우드의 각 기능들 소개
Discovery 서버부터 살펴보자.
그 전에 각 기능의 목차는 MSA에서 통상적으로 부르는 용어(Discovery)와
Netflix OSS에서 지원하는 기능을 일컫는 용어(Eureka) 순서로 소개할 예정이다.
아래처럼 말이다.
예시 - Discovery (Eureka)
Discovery (Eureka)
디스커버리(Discovery)는 사용되는 서비스 모듈(Gateway, Config, Server)들의 정보를 중앙 집중식으로 등록해서 관리하는 서버를 말한다.
스프링 클라우드에서는 디스커버리 서버는 보통 유레카(Eureka) 서버를 사용한다.
디스커버리 서버는 말 그대로 각각의 모듈을 관리하는 용도이다.
즉, 관리가 필요없을 수도 있으니 말 그대로 MSA 환경에서 디스커버리 서버가 없다고 해서 돌아가지 않는 것은 아니다.
하지만 MSA 환경에서 디스커버리는 중요한 역할을 맡고 있으며 그렇기에 디스커버리 서버가 어떤 기능을 도와주는지 아는 것이 중요하다.
디스커버리 서버가 있는 경우 각각의 마이크로서비스를 동적으로 관리하는 기능을 제공한다는 점이다.
이 말이 무슨 말이냐면 유레카를 통해 서비스를 추적하고 동적으로 서비스의 상태 변화를 감지하여 효과적인 서비스를 제공해준다는 뜻이다.
예를 들어 대표적으로 유레카 서버에는 서비스에 대한 인스턴스 정보가 등록되어있으니 서비스들끼리 통신이 필요할 때 유레카 서버에 등록된 인스턴스 정보를 가져와서 사용할 수 있다.
유레카는 유레카 서버와, 유레카 클라이언트로 나뉜다.
유레카 클라이언트라고 하면 실제 개별 마이크로서비스를 일컫는 말이라고 보면 된다.
위의 그림을 보면 마치 Config과 Gateway도 디스커버리 안에 속해있어서 유레카 클라이언트라고 불리지만 유레카 클라이언트로 부르진 않는다.
Gateway (Zuul)
게이트웨이(Gateway)는 위의 사진처럼 외부 요청을 받는 통로를 말한다.
그렇기에 위의 유레카와는 달리 스프링 클라우드 환경에서 필수적인 요소라고 볼 수 있다.
L7 영역에서 작동한다.
하지만 Netflix OSS에서 제공하던 줄(Zuul)은 지원 중단되었고 Spring 진영에서 자체적으로 만든 Spring Cloud Gateway를 쓰는 것이 좋다.
차이점이 있다면 Zuul 1은 Tomcat, Zuul 2는 Netty를 이용하여 만들어졌고 Spring Cloud Gateway는 Netty 기반의 Webflux를 이용해서 만들어졌다.
결과적으로 Zuul은 더 이상 지원하지 않으니 Spring Cloud Gateway를 사용하는 것이 좋다.
게이트웨이는 서버 사이드 로드밸런싱을 수행한다.
Gateway Server가 외부로 부터 받은 요청을 전부 로드밸런싱으로 트래픽 분산을 해주는 형태를 말한다.
참고로 Spring Cloud Gateway에는 아래의 의존성을 추가하면 안된다.
org.springframework.boot:spring-boot-starter-webSpring Cloud Gateway에 위의 의존성을 추가하면 에러가 발생한다.
위의 의존성은 Spring MVC 환경을 위한 의존성이며 톰캣 서버가 추가되는 것이라 Netty 서버 기반으로 돌아가는 Spring Cloud Gateway에서는 충돌 에러가 발생한다.
그 외(Config, Histrix, Ribbon)
그 외라고 정리한 이유는 Spring Cloud 환경에서 MSA에 대한 구조를 배우기 위한 목적으로는 Config, Histrix, Ribbon은 우선순위에 있다라고 볼 수 없기 때문이다.
Config
각각의 모듈이 참조하는 설정 파일을 중앙 집중식으로 관리하는 서버를 말한다.
말 그대로 필수는 아니지만 필요한 기능 중 하나이다.
예를 들어 DB 연결을 각각의 서비스가 다 붙을 순 없으니 Config Server에서 DB를 붙이면 각각의 서비스에 다 전파된다.
Circuit Breaker (Histrix)
서킷 브레이커(Circuit Breaker)는 분산 시스템에서 장애가 발생했을 때, 해당 서비스에 대한 호출을 중단하고 실패한 요청을 처리하기 위한 대체 동작을 수행하는 기능을 제공한다.
Histrix도 역시 Netflix OSS에서 지원 중단되었으니 Resilience4j와 같은 라이브러리를 통해서 서킷브레이커 기능을 구현해야한다.
Load Balancer (Ribbon)
Ribbon은 클라이언트 사이드 로드밸런싱을 수행한다.
위에서 게이트웨이는 서버 사이드 로드밸런싱을 수행한다고 설명했다.
각각의 기능은 장단점이 존재한다.
서버 사이드에서 로드밸런싱을 할 경우 SPOF(Single Point of Failure)라고 해서 게이트웨이 서버가 죽으면 전체 서버가 죽는다는 단점이 존재한다.
다만, 한 곳에서 관리할 수 있으니 편하다라는 장점이 있고 클라이언트 사이드 로드 밸런싱은 Ribbon을 통해서 구현하는데 이렇게 하면 각각의 클라이언트 서비스에서 로드 밸런싱 기능을 다 일일이 구현해줘야한다라는 단점이 존재한다.
장점이라고 하면 당연하게도 SPOF가 발생하지 않는다는 것이다.
Ribbon 역시 지원중단 되었으므로 Spring Cloud LoadBalancer를 사용하는 것이 좋다고 한다.
실행 순서
인텔리제이에서 MSA 환경으로 개발하면 하단에 Services 탭에서 실행시키겠냐는 알림이 뜬다.
그럼 아래와 같이 각각의 모듈 순서를 정해서 한꺼번에 실행시킬 수 있게 된다.

순서는 유레카 서버 -> Config -> 유레카 클라이언트 순서로 실행시킨다.
유레카 클라이언트부터 켜게되면 유레카 서버가 해당 클라이언트를 인식하지 못한다.
물론 순서대로 켰다고해서 서비스가 바로 실행되는건 아니다.
[Load balancer does not contain an instance for the service post]
위 에러가 뜨면 서비스 올리고 난 후에 바로 실행을 하려고 하면 종종 위의 에러를 볼 수 있는데 바로 유레카 서버에 아직 유레카 클라이언트가 안붙은거라고 볼 수 있다.
인텔리제이에서 파일 찾기
Ctrl Shift N으로 파일 찾기를 통해서 파일을 찾으면 중복된 파일이 여러개 검색될 수 있다. 그럴때는 아래와 같이 특정 프로젝트 모듈 선택해서 찾을 수 있다.