부하 테스트로 알아본 적절한 DB 선택(RDBMS, OpenSearch, MongoDB)
기존에 NoSQL은 정규화가 필요하지 않은 데이터를 효율적으로 저장하거나 조회하기 위해 OpenSearch, MongoDB 등을 선택할 수 있다고 생각했습니다.
실제로 이 것에 관해 Json 타입의 데이터를 어디에 넣을지 고민한 글도 있습니다.
물론 이 말도 틀린 말은 아닙니다.
하지만 이번에 DB에 대한 부하 테스트를 해보면서 NoSQL을 선택할 더 중요한 이유를 찾게 되었고 단순히 데이터의 형태에 따라 DB를 결정하는 것이 아닌 기능 요구 사항에 따라 적절한 DB를 어떻게 선택할 수 있을지 고민할 수 있게 되어서 글을 작성합니다.
일단 거두절미하고 바로 결과를 보겠습니다.
부하 테스트 결과
부하 테스트는 K6로 진행했으며 5초마다 유저 사용량이 100명씩 증감되어 총 100~500명이 25초 동안 이용하는 시뮬레이션으로 진행했습니다.
요구 사항
테스트하고자 하는 요구 사항은 회원 정보 현황 업데이트입니다.
특정 회원이 로그인을 한다면 로그인 된 시간, IP 등을 관리자가 볼 수 있도록 Update 하거나 첫 로그인이라면 Insert 하는 것입니다.
여러분들이라면 어떻게 구현하시겠나요?
userRepositry.save(user);
가장 저에게 익숙한 JPA 코드가 먼저 생각나는데요.
save를 이용하면 Insert 뿐만 아니라 Update도 처리할 수 있기 때문에 깔끔하게 처리할 수 있습니다.
하지만 사용량이 급격하게 많아져서 500명 혹은 5000명이 동시에 이용한다면 어떤 DB에 저장하면 좋을까요?
우선 해당 요구 사항을 MySQL을 이용해 처리해보겠습니다.
RDBMS
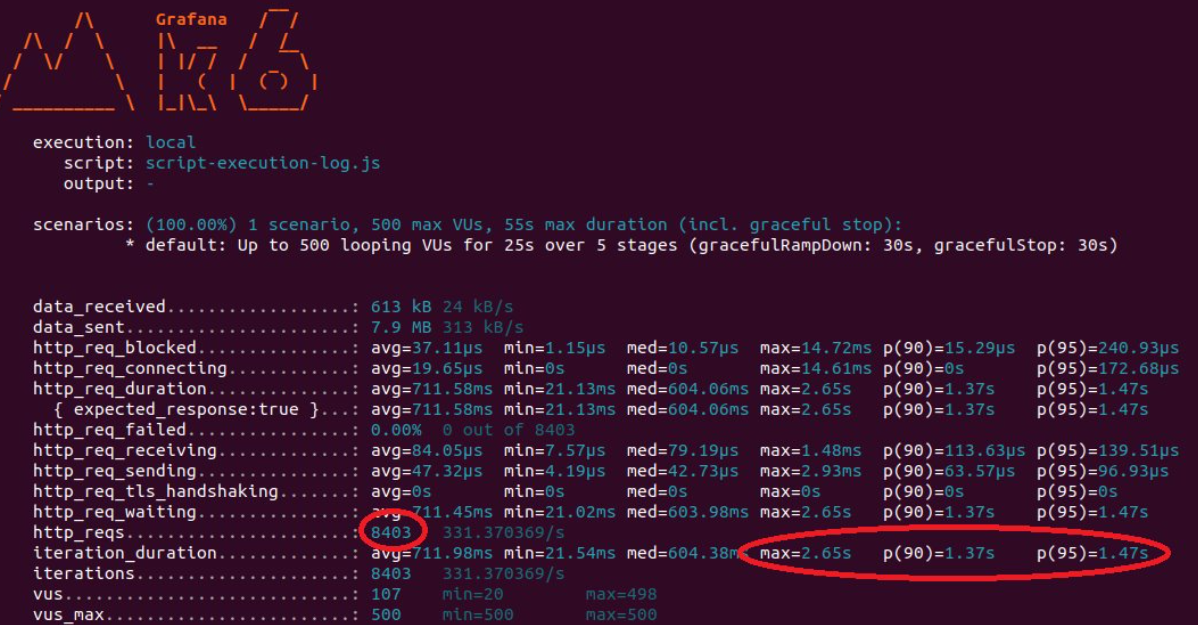
약 25초동안 100~500명의 사용자의 비즈니스 로직 처리가 8403건 완료되었고 최대로 오래 기다린 사람은 2.65초입니다.
만약 500명이 아닌 1000~5000명으로 늘린다면 어떻게 될까요?
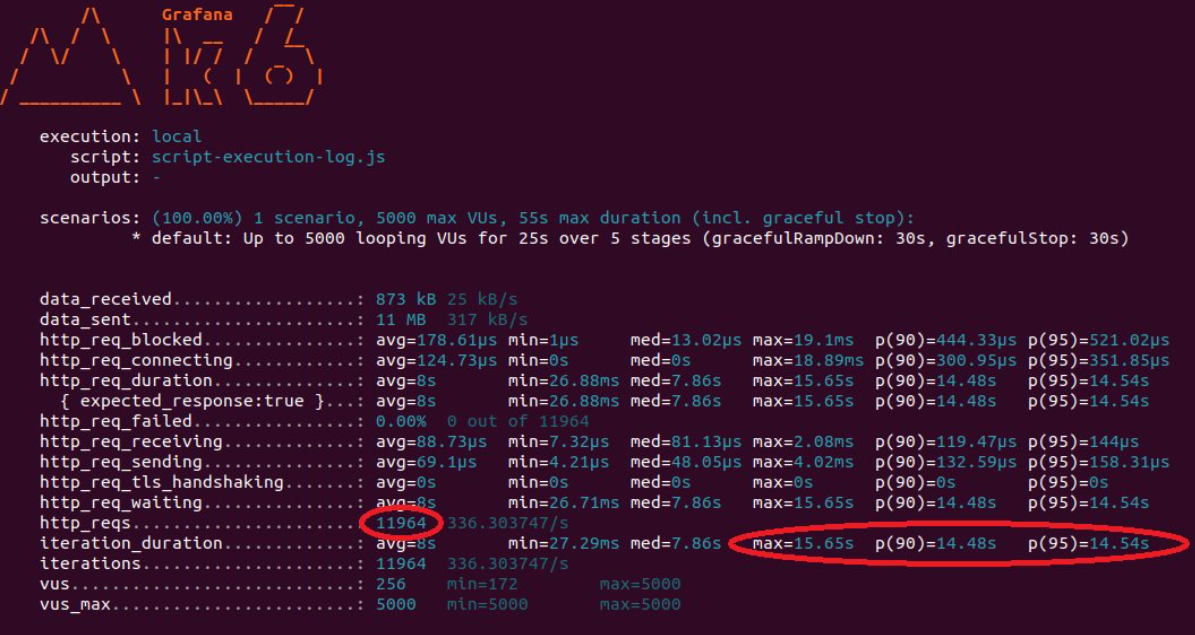
5000명이나 인입이 되었는데도 처리량이 그렇게 늘어나지 않은 11964건이 처리되고 최대로 오래 기다린 사람은 15.65초입니다.
물론 이 과정에서 Time-Out은 발생하지 않았고 모두 정상 처리 되었지만 사용량이 좀 더 많아진다면 Time-Out이 발생하는 사용자도 생길 것입니다.
이렇게 느리게 처리된 이유는 일단 DB 처리가 끝날 때까지 Tomcat Thread가 대기 상태에 놓여있게 되어서 그렇습니다.
같은 조건으로 OpenSearch를 테스트해보겠습니다.
OpenSearch
OpenSearch는 Spring Boot에서 Kafka와 Logstash를 연동해서 처리하도록 구현되어 있습니다.
그러므로 Spring Boot에서 실제로 저장하는 로직이 존재하지 않기 때문에 비동기적 처리가 가능합니다.
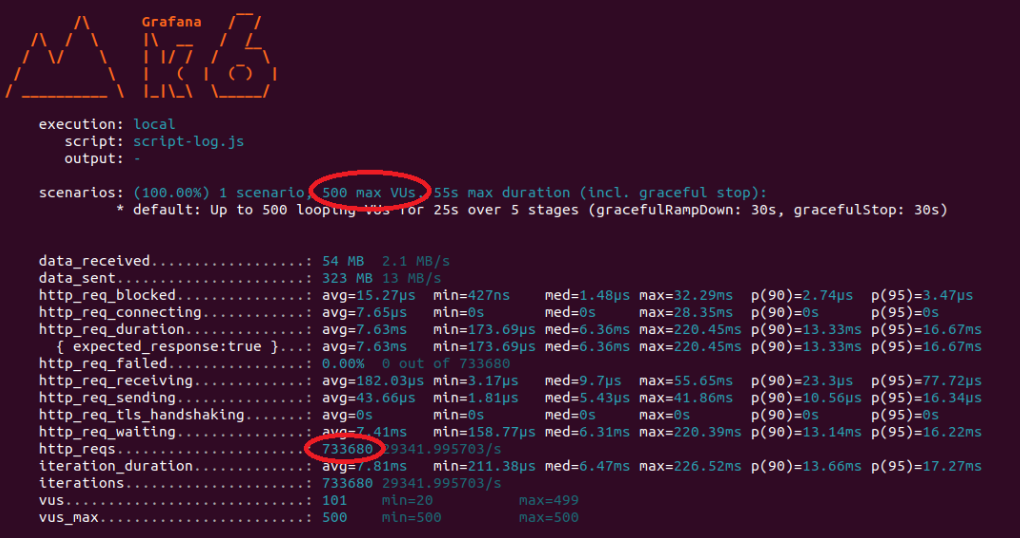
결과는 500명의 사용자가 무려 733680건을 성공하게 되었습니다.
기다린 시간도 마이크로 세컨드로 소요된 시간도 굉장히 짧아진 것을 볼 수 있었습니다.
두 개의 테스트를 비교하는 것 만으로 단순히 정규화 데이터인지 아닌지를 떠나서 어디에 저장하는 것이 좋을지 고민하게 되지 않나요?
RDBMS에 저장하는 방식
RDBMS부터 한번 생각해 보겠습니다.
DB 처리가 굉장히 느려서 Tomcat Thread가 묶이는 현상이 있었고 서버의 처리량이 느려진 걸 확인할 수 있었습니다.
Kafka를 써볼까?
이 문제를 해결하기 위해 가장 직관적으로 떠올랐던 것은 Spring에서 처리할 데이터를 Kafka에 토픽을 생성해서 전달한 뒤 토픽을 소모하는 서버를 만들어서 DB에 간접적으로 저장하도록 구현하면 기존 서버의 부하는 해소할 수 있다고 생각했습니다.
하지만 위와 같은 방식은 일반적인 RDBMS 처리 방식이 아닙니다.
결과적으로 일부분 비동기적인 특성을 이용한 것인데, 이렇게 사용해 버린다면 RDBMS의 특성이 몇 가지 사라지게 됩니다.
일단 문제점 몇 개를 살펴보겠습니다.
실질적인 DB 부하가 개선되지 않는다.
서버를 나누는 것으로는 기존 서버의 부하는 해결됐지만 새로 만든 서버에서는 여전히 부하도 걸리고 실제 DB 처리가 느렸던 부분은 해결되지 않은 상태입니다.
트랜잭션 처리가 의미가 없어집니다.
또 다른 문제는 RDBMS의 트랜잭션 처리가 일부분 의미가 사라집니다.
물론 서버를 나눠서 처리하는 것에도 ACID의 특성으로 인해 데이터의 무결성은 지킬 수 있지만 사용자가 데이터의 처리에 대한 반환 값을 받지 못한다는 것입니다.
다시 말해 클라이언트의 데이터는 이미 Kafka로 넘겨지고 끝났기 때문에 데이터의 처리가 트랜잭션 과정에서 실패를 했는지 성공했는지 알 수 없습니다.
물론 이런 경우는 대표적으로 Netty를 기반으로 한 WebFlux와 같은 비동기 프로그래밍을 사용하면 비동기적인 특성을 살리면서 데이터를 저장할 수도 있고 결과 값을 반환받을 수도 있습니다.
WebFlux와 같은 대체 프레임워크가 존재하는데 Kafka를 이용해 반쪽짜리(저장만 하고 결과 값을 받지 않는) 비동기를 구현하는 것은 오히려 복잡도만 올라가게 됩니다.
WebFlux를 써볼까?
위에서 꺼낸 주제인 WebFlux를 이용해 보면 어떨까요?
실제로 서버의 부하는 줄어들겠지만 트랜잭션 처리를 하면서 데이터를 저장하는 과정은 여전히 느릴 수밖에 없습니다.
R2DBC에서는 DB를 쓰고 읽는 과정을 비동기로 하는 것뿐이지 실제 I/O 입력 과정은 여전히 느릴 테니까요.
여기서 또 하나 알 수 있는 점은 Tomcat을 쓰든 WebFlux를 쓰든 사용자는 데이터의 결과를 보장받는다는 것입니다.
그게 RDBMS를 쓰는 것의 핵심적인 특성입니다.
결과를 보장받아야만 하는 상황이라면 어떤 상황을 의미할까요?
대표적으로 이체 과정이 그렇습니다.
만약에 이체 버튼을 눌렀는데 처리가 완료가 되지 않았지만 비동기적 처리를 해서 완료 페이지가 보인다면 사용자는 완료가 되었다고 판단할 수 있습니다.
그렇기에 이체 같은 중요한 시스템은 RDBMS를 사용해서 정말 완료되었을 때 확인할 수 있도록 설계해야 합니다.
이런 상황에서 발생하는 속도 문제는 Kafka가 아닌 WebFlux, Redis와 같은 캐시 시스템, 인덱스 설계, 쿼리문 등을 적절하게 섞어가며 효율적이게 만들고 부하가 또 발생한다면 시스템의 성능을 향상하는 방식으로 사용하게 됩니다.
결론적으로 어떠한 방식이든 제가 처음에 원했던 요구 사항을 충족할만한 방법은 없습니다.
회원 정보 현황을 업데이트하는 것에는 캐시, 인덱스, 쿼리문 등이 필요한 영역은 아니고 WebFlux를 쓴다고 하더라도 비동기로 처리할 뿐이지 DB에서 트랜잭션을 이용해 데이터를 삽입하는 과정 자체가 느린 것은 해결되지 않기 때문입니다.
OpenSearch에 저장하는 방식
이제 OpenSearch를 알아보겠습니다.
OpenSearch는 대표적으로 로그를 저장하는 데 쓰입니다.
RDBMS를 사용했을 때는 사용자가 데이터에 대한 Request > Save > Response의 Flow를 하나의 묶음으로 처리해야 하는 특성을 가졌다면 굳이 결과를 받지 않아도 되는 로그 시스템 같은 경우는 대부분 OpenSearch를 이용하게 됩니다.
사용자는 Request만 보내면 끝이니까요.
그러므로 결론적으로 단방향으로 Insert만 하는 경우에는 OpenSearch를 쓰는 것이 좋습니다.
근데 요구 사항은 Insert가 아닌 Upsert였습니다.
이 경우에는 OpenSearch를 쓰는 것이 올바르지 않습니다.
OpenSearch는 Lucene 기반으로 만들어져 있으며 Lucene의 Segment 단위는 Immutable 한 특성을 유지하기 때문입니다.
즉, 한번 저장되면 변경되지 않고 유지되는 방식을 이용해 검색에서 최적화가 가능하도록 유지합니다.
그럼에도 불구하고 OpenSearch는 Update 기능을 제공하지만 만약에 Update를 하게 된다면 기존의 문서를 삭제하고 새 문서를 다시 만들게 됩니다.
그러니까 Delete > Insert 방식으로 이루어지게 되어서 전반적인 OpenSearch 성능 저하가 오게 됩니다.
MongoDB에 저장하는 방식
이럴 때 가장 효율적인 방식은 MongoDB라고 결론을 내렸습니다.
MongoDB는 CRUD를 자유롭게 지원하고 전통적인 RDBMS보다 고속 쓰기/읽기가 가능합니다.
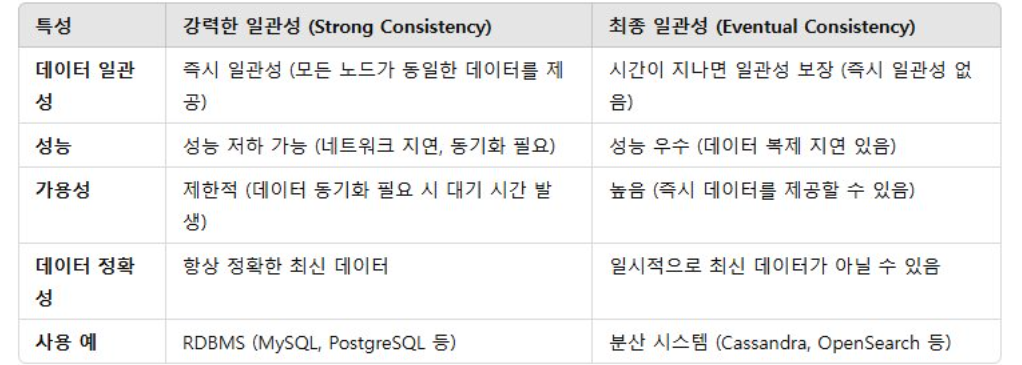
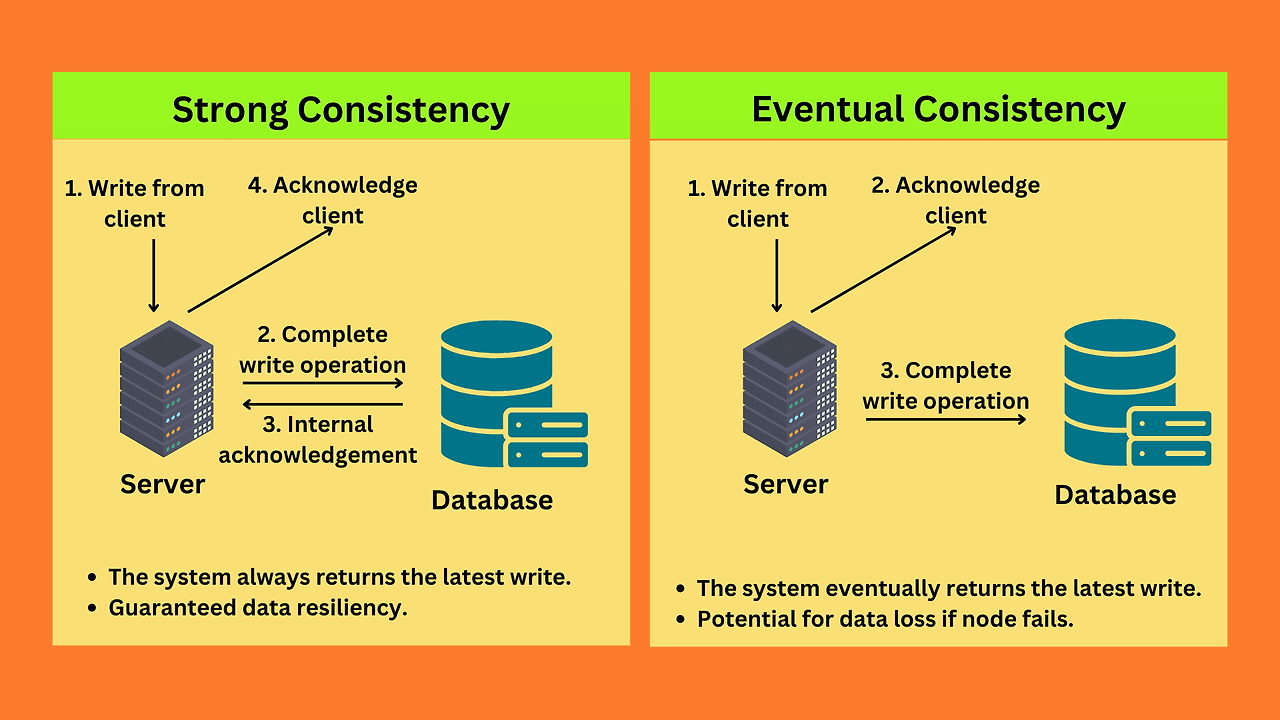
여기서 대표적으로 비교되는 것이 강력한 일관성과 최종 일관성인데요.
MongoDB와 OpenSearch가 대표적으로 최종 일관성 방식을 선택합니다.
데이터 저장을 하고 나면 바로 반영하는 것이 아니라 추후에 반영한다는 의미입니다.
강력한 일관성과 최종 일관성을 선택하는 것은 어느 정도 트레이드오프가 발생하고 엄격한 데이터 정확성이 필요한 경우(예: 금융 시스템)에는 일반적으로 강력한 일관성을 선택하는 반면, 더 나은 성능과 가용성을 위해 일시적인 불일치를 허용할 수 있는 애플리케이션(예: SNS 피드)은 최종 일관성을 선택할 수 있습니다.
RDBMS는 쓰기, 읽기가 하나의 흐름으로 이어지기 때문에 강력한 일관성을 유지하므로 사용자는 저장한 데이터를 바로 조회할 수 있지만 오히려 DB 처리 속도 저하가 생겼습니다.
MongoDB는 최종 일관성으로 쓰기 작업이 나중에 반영된다는 특성이 있지만 가용성과 속도 측면에서 장점이 있습니다.
즉, 최종 일관성은 성능과 가용성을 우선시하며, 즉각적인 데이터 일관성에 대한 트레이드오프가 있습니다.
결론적으로 처음의 회원 정보 현황 업데이트에 대한 요구사항은 강력한 일관성이 필요하지도 않고 나중에 반영만 되면 상관없었습니다. 그리고 속도 측면과 Update 기능이 동시에 필요했기 때문에 MongoDB를 이용하는 것이 가장 효율적이었다는 것을 알 수 있습니다.
정규화된 데이터라도 NoSQL을 이용할 수도 있고 비정형 데이터여도 RDBMS를 이용할 수 있습니다.
여기서 알 수 있는 점은 NoSQL의 기본이 되는 특징을 알 수 있는데요.
NoSQL은 비정형 데이터를 다루기 위해 만든 것이라기 보다는 고속 처리를 하기 위해 비정형 데이터를 사용한 것으로 생각할 수 있습니다.
그러므로 NoSQL의 선택의 기준은 NoSQL이 왜 만들어졌는지부터 알아야 더 좋은 선택이 될 수 있다는 걸 알게 되었습니다.